谈到Redis缓存,我们描述其性能时会这么说:支持1万并发连接,几万QPS。而我们描述Nginx的高性能时,则会宣示:支持C10M(1千万并发连接),百万级QPS。Redis与Nginx同样使用了事件驱动、异步调用、Epoll这些机制,为什么Nginx的并发连接会高出那么多呢?(本文不讨论Redis分布式集群) 这其实是由进程架构决定的。为了让进程占用CPU的全部计算力,Nginx充分利用了分时操作系统的特点,比如增加CPU时间片、提高CPU二级缓存命中率、用异步IO和线程池的方式回避磁盘的阻塞读操作等等,只有清楚了Nginx的这些招数,你才能将Nginx的性能最大化发挥出来。 为了维持Worker进程间的负载均衡,在1.9.1版本前Nginx使用互斥锁,基于八分之七这个阈值维持了简单、高效的基本均衡。而在此之后,使用操作系统提供的多ACCEPT队列,Nginx可以获得更高的吞吐量。 本文将会沿着高性能这条主线介绍Nginx的Master/Worker进程架构,包括进程间是如何分担流量的,以及默认关闭的多线程模式又是如何工作的。同时,本文也是Nginx开源社区基础培训系列课程第一季,即6月18日晚第3次直播课的部分文字总结。
如何充分使用多核CPU?
由于散热问题,CPU频率已经十多年没有增长了。如下图统计了1970年到2018年间CPU性能的变化,可以看到表示频率的绿色线从2005年后就不再升高,服务器多数都在使用能耗比更经济的2.x GHz CPU:  (图片来源:https://www.karlrupp.net/2018/02/42-years-of-microprocessor-trend-data/) 我们知道,CPU频率决定了它的指令执行速度,当频率增长陷入瓶颈,这意味着所有单进程、单线程的软件性能都无法从CPU的升级上获得提升,包括本文开头介绍的Redis服务就是如此。如果你熟悉JavaScript语言,可能使用过NodeJS这个Web服务,虽然它也是高并发服务的代表,但同样受制于单进程、单线程架构,无法充分CPU资源。 CPU厂商对这一问题的解决方案是横向往多核心发展,因此上图中表示核心数的黑色线至2005年后快速上升。由于操作系统使用CPU核心的最小单位是线程,要想同时使用CPU的所有核心,软件必须支持多线程才行。当然,进程是比线程更大的调度粒度,所以多进程软件也是可以的,比如Nginx。 下图是Nginx的进程架构图,可以看到它含有4类进程:1个Master管理进程、多个Worker工作进程、1个Cache Loader缓存载入进程和1个Cache Manager缓存淘汰进程。
(图片来源:https://www.karlrupp.net/2018/02/42-years-of-microprocessor-trend-data/) 我们知道,CPU频率决定了它的指令执行速度,当频率增长陷入瓶颈,这意味着所有单进程、单线程的软件性能都无法从CPU的升级上获得提升,包括本文开头介绍的Redis服务就是如此。如果你熟悉JavaScript语言,可能使用过NodeJS这个Web服务,虽然它也是高并发服务的代表,但同样受制于单进程、单线程架构,无法充分CPU资源。 CPU厂商对这一问题的解决方案是横向往多核心发展,因此上图中表示核心数的黑色线至2005年后快速上升。由于操作系统使用CPU核心的最小单位是线程,要想同时使用CPU的所有核心,软件必须支持多线程才行。当然,进程是比线程更大的调度粒度,所以多进程软件也是可以的,比如Nginx。 下图是Nginx的进程架构图,可以看到它含有4类进程:1个Master管理进程、多个Worker工作进程、1个Cache Loader缓存载入进程和1个Cache Manager缓存淘汰进程。 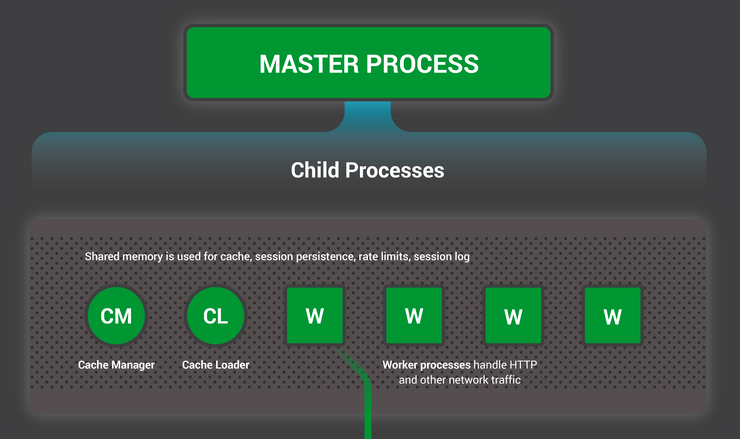 其中,Master是管理进程,它长期处于Sleep状态,并不参与请求的处理,因此几乎不消耗服务器的IT资源。另外,只有在开启HTTP缓存后,Cache Loader和Cache Manager进程才存在,其中,当Nginx启动时加载完磁盘上的缓存文件后,Cache Loader进程也会自动退出。关于这两个 Cache进程,我会在后续介绍Nginx缓存时中再详细说明。 负责处理用户请求的是Worker进程,只有Worker进程能够充分的使用多核CPU,Nginx的QPS才能达到最大值。因此,Worker进程的数量必须等于或者大于CPU核心的数量。由于Nginx采用了事件驱动的非阻塞架构,繁忙时Worker进程会一直处于Running状态,因此1个Worker进程就能够完全占用1个CPU核心的全部计算力,如果Worker进程数超过了CPU核心数,反而会造成一些Worker进程因为抢不到CPU而进入Sleep状态休眠。所以,Nginx会通过下面这行代码自动获取到CPU核心数:
其中,Master是管理进程,它长期处于Sleep状态,并不参与请求的处理,因此几乎不消耗服务器的IT资源。另外,只有在开启HTTP缓存后,Cache Loader和Cache Manager进程才存在,其中,当Nginx启动时加载完磁盘上的缓存文件后,Cache Loader进程也会自动退出。关于这两个 Cache进程,我会在后续介绍Nginx缓存时中再详细说明。 负责处理用户请求的是Worker进程,只有Worker进程能够充分的使用多核CPU,Nginx的QPS才能达到最大值。因此,Worker进程的数量必须等于或者大于CPU核心的数量。由于Nginx采用了事件驱动的非阻塞架构,繁忙时Worker进程会一直处于Running状态,因此1个Worker进程就能够完全占用1个CPU核心的全部计算力,如果Worker进程数超过了CPU核心数,反而会造成一些Worker进程因为抢不到CPU而进入Sleep状态休眠。所以,Nginx会通过下面这行代码自动获取到CPU核心数:
1 | ngx_ncpu = sysconf(_SC_NPROCESSORS_ONLN); |
如果你在nginx.conf文件中加入下面这行配置:
1 | worker_processes auto; |
Nginx就会自动地将Worker进程数设置为CPU核心数:
1 | if (ngx_strcmp(value[1].data, "auto") == 0) { |
为了防止服务器上的其他进程占用过多的CPU,你还可以给Worker进程赋予更高的静态优先级。Linux作为分时操作系统,会将CPU的执行时间分为许多碎片,交由所有进程轮番执行。这些时间片有长有短,从5毫秒到800毫秒不等,内核分配其长短时,会依据静态优先级和动态优先级。其中,动态优先级由内核根据进程类型自动决定,比如CPU型进程就能比IO型进程获得更长的时间片,而静态优先级可以通过setpriority函数设置。 在Linux中,静态优先级共包含40级,从-20到+19不等,其中-20表示最高优先级。进程的默认优先级是0,所以你可以通过调级优先级,让Worker进程获得更多的CPU资源。在nginx.conf文件中,worker_priority配置就能设置静态优先级,比如:
1 | worker_priority -10; |
由于每个CPU核心都拥有一级、二级缓存(Intel的Smart Cache三级缓存是所有核心共享的),为了提高这两级缓存的命中率,还可以将Worker进程与CPU核心绑定在一起。CPU缓存由于离计算单元更近,而且使用了更快的存储介质,所以二级缓存的访问速度不超过10纳秒,相对应的,主存存取速度至少在60纳秒以上,因此频繁命中CPU缓存,可以提升Nginx指令的执行速度。在nginx.conf中你可以通过下面这行配置绑定CPU:
1 | worker_cpu_affinity auto; |
Nginx的多进程架构已经能够支持C10M级别的高并发了,那么Nginx中的多线程又是怎么回事呢?这要从Linux文件系统的非阻塞调用说起。 Worker进程上含有数万个并发连接,在处理连接的过程中会产生大量的上下文切换。由于内核做一次切换的成本大约有5微秒,随着并发连接数的增多,这一成本是以指数级增长的。因此,只有在用户态完成绝大部分的切换,才有可能实现高并发。想做到这一点,只有完全使用非阻塞的系统调用。对于网络消息的传输,non-block socket可以完美实现。然而,Linux上磁盘文件的读取却是个大问题。 我们知道,机械硬盘上定位文件很耗时,由于磁盘转速难以提高(服务器磁盘的转速也只有10000转/秒),所以定位操作需要8毫秒左右,这是一个很高的数字。写文件时还可以通过Page Cache磁盘高速缓存的write back功能,先写入内存再异步回盘,读文件时则没有好办法。虽然Linux提供了原生异步IO系统调用,但在内存紧张时,异步AIO会回退到阻塞API(FreeBSD操作系统上的AIO没有这个问题)。 所以,为了缩小阻塞API的影响范围,Nginx允许将读文件操作放在独立的线程池中执行。比如,你可以通过下面这2条配置,为HTTP静态资源服务开启线程池:
1 | thread_pool name threads=number [max_queue=number]; |
这个线程池是运行在Worker进程中的,并通过一个任务队列(max_queue设置了队列的最大长度),以生产者/消费者模型与主线程交换数据,如下图所示: 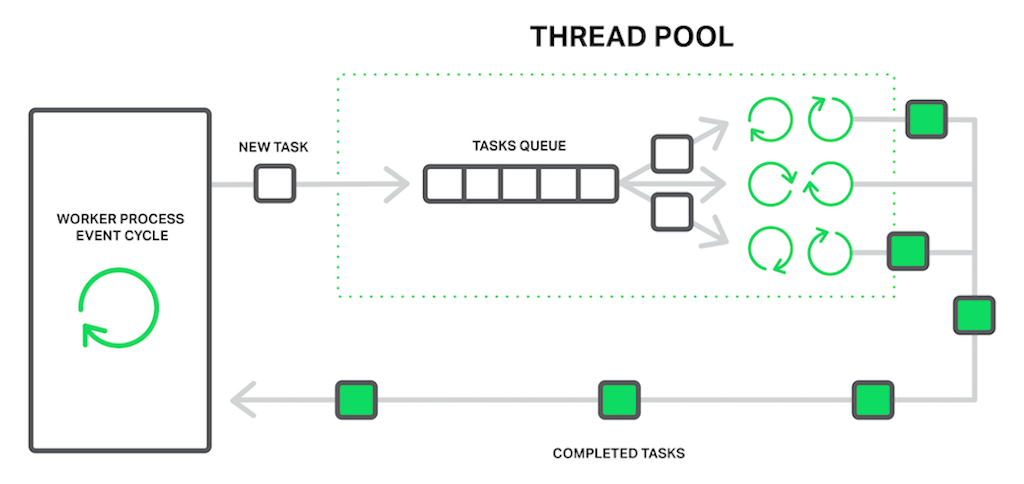 在极端场景下(活跃数据占满了内存),线程池可以将静态资源服务的性能提升9倍,具体测试可以参见这篇文章:https://www.nginx.com/blog/thread-pools-boost-performance-9x/。 到这里你可能有个疑问:又是多进程,又是多线程,为什么Nginx不索性简单点,全部使用多线程呢?这主要由2个原因决定:
在极端场景下(活跃数据占满了内存),线程池可以将静态资源服务的性能提升9倍,具体测试可以参见这篇文章:https://www.nginx.com/blog/thread-pools-boost-performance-9x/。 到这里你可能有个疑问:又是多进程,又是多线程,为什么Nginx不索性简单点,全部使用多线程呢?这主要由2个原因决定:
- 首先,作为高性能负载均衡,稳定性非常重要。由于多线程共享同一地址空间,一旦出现内存错误,所有线程都会被内核强行终止,这会降低系统的可用性;
- 其次,Nginx的模块化设计允许第三方代码嵌入到核心流程中执行,这虽然大大丰富了Nginx生态,却也引入了风险。
因此,Nginx宁肯选用多进程模式使用多核CPU,而只以多线程作为补充。
Worker进程间是如何协同处理请求的?
当一个进程监听了80端口后,其他进程绑定该端口时会失败,通常你会看到“Address already in use”的提示。那么,所有Worker进程同时监听80或者443端口,又是怎样做到的呢? 如果你用netstat命令,可以看到只有进程ID为2758的Master进程监听了端口: 
Worker进程是Master的子进程,用ps命令可以从下图中看到,2758有2个Worker子进程,ID分别为3188和3189: 
由于子进程自然继承了父进程已经打开的端口,所以Worker进程也在监听80和443端口,你可以用lsof命令看到这一点: 
我们知道,TCP的三次握手是由操作系统完成的。其中,成功建立连接的socket会放入ACCEPT队列,如下图所示: 
这样,当Worker进程通过epoll_wait的读事件(Master进程不会执行epoll_wait函数)获取新连接时,就由内核挑选1个Worker进程处理新连接。早期Linux内核的挑选算法很糟糕,特别是1个新连接建立完成时,内核会唤醒所有阻塞在epoll_wait函数上的Worker进程,然而,只有1个Worker进程,可以通过accept函数获取到新连接,其他进程获取失败后重新休眠,这就是曾经广为人知的“惊群”现象。同时,这也很容易造成Worker进程间负载不均衡,由于每个Worker进程绑定1个CPU核心,当部分Worker进程中的并发TCP连接过少时,意味着CPU的计算力被闲置了,所以这也降低了系统的吞吐量。 Nginx早期解决这一问题,在通过应用层accept_mutex锁完成的,在1.11.3版本前它是默认开启的:
1 | accept_mutex on; |
这把锁的工作原理是这样的:同一时间,通过抢夺accept_mutex锁,只有唯一1个持有锁的Worker进程才能将监听socket添加到epoll中:
1 | if (ngx_shmtx_trylock(&ngx_accept_mutex)) { |
这就解决了“惊群”问题,我们再来看负载均衡功能是怎么实现的。在nginx.conf中可以通过下面这行配置,设定每个Worker进程能够处理的最大并发连接数:
1 | worker_connections number; |
当空闲连接数不足总数的八分之一时,Worker进程会大幅度降低获取accept_mutex锁的概率:
1 | ngx_int_t ngx_accept_disabled = ngx_cycle->connection_n / 8 - ngx_cycle->free_connection_n; |
我们还可以通过accept_mutex_delay配置控制负载均衡的执行频率,它的默认值是500毫秒,也就是最多500毫秒后,并发连接数较少的Worker进程会尝试处理新连接:
1 | accept_mutex_delay 500ms; |
当然,在1.11.3版本后,Nginx默认关闭了accept_mutex锁,这是因为操作系统提供了reuseport(Linux3.9版本后才提供这一功能)这个更好的解决方案。我们先来看一下处理新连接的性能对比图: 
上图中,横轴中的default项开启了accept_mutex锁。可以看到,使用reuseport后,QPS吞吐量有了3倍的提高,同时处理时延有明显的下降,特别是时延的波动(蓝色的标准差线)有大幅度的下降。 reuseport能够做到这么高的性能,是因为内核为每个Worker进程都建立了独立的ACCEPT队列,由内核将建立好的连接按负载分发到各队列中,如下图所示: 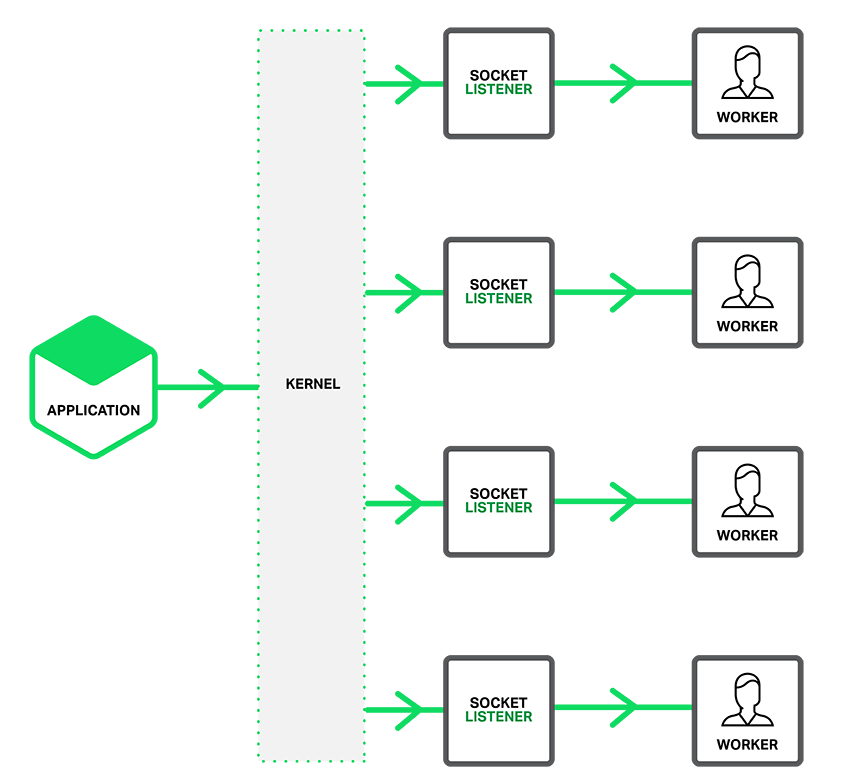
这样,Worker进程的执行效率就高了很多!如果你想开启reuseport功能,只需要在listen指令后添加reuseport选项即可: 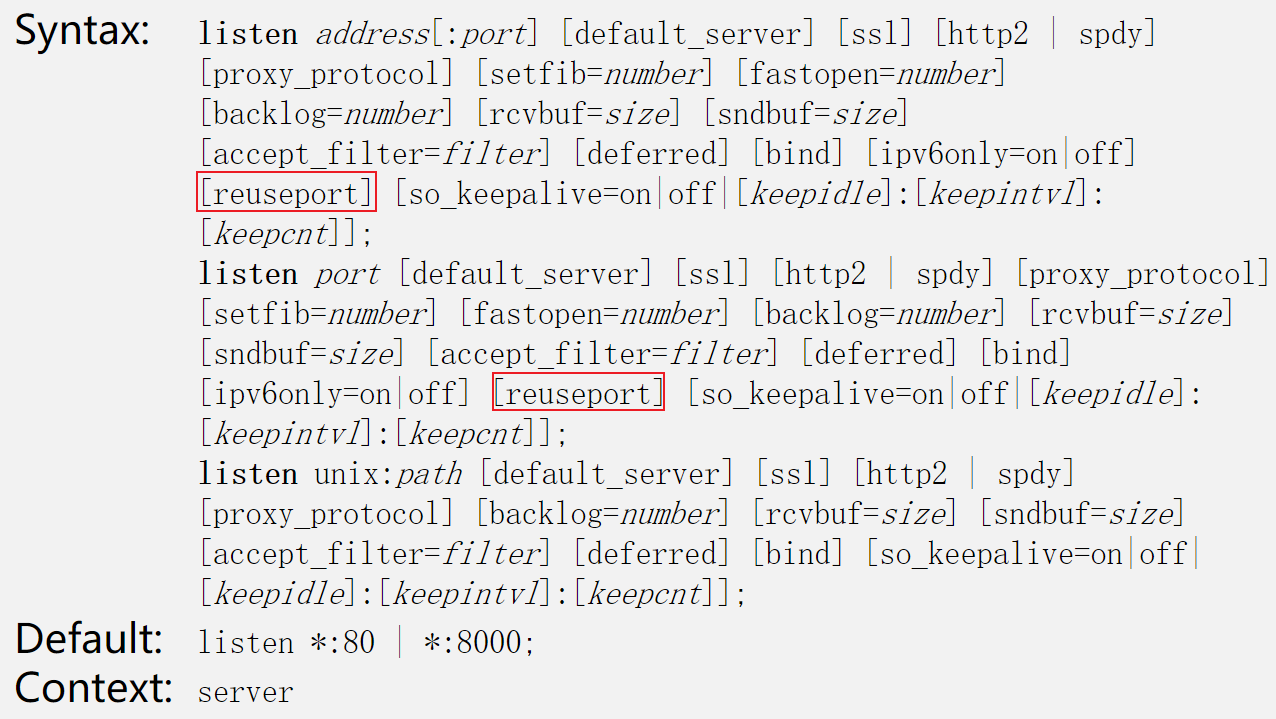
当然,Master/Worker进程架构带来的好处还有热加载与热升级。在https://www.nginx-cn.net/article/70这篇文章中,我对这一流程有详细的介绍。
小结
最后对本文的内容做个总结。 材料、散热这些基础科技没有获得重大突破前,CPU频率很难增长,类似Redis、NodeJS这样的单进程、单线程高并发服务,只能向分布式集群方向发展,才能继续提升性能。Nginx通过Master/Worker多进程架构,可以充分使用服务器上百个CPU核心,实现C10M。
为了榨干多核CPU的价值,Nginx无所不用其极:通过绑定CPU提升二级缓存的命中率,通过静态优先级扩大时间片,通过多种手段均衡Worker进程之间的负载,在独立线程池中隔离阻塞的IO操作,等等。可见,高性能既来自于架构,更来自于细节。