有同学反馈:在配置Nginx四层限速时,proxy_upload_rate和proxy_download_rate有一定的概率不生效。我按照他的步骤也能复现,但这与官方Nginx很稳定(相对其他开源软件)的印象并不相符,是不是Nginx的官方BUG呢?这里的真实原因,其实是Nginx字节限速机制与时间更新频率的协商导致的,这篇文章我们就来研究下Nginx的字节限速。
首先看下测试场景:基于UDP协议搭建四层代理(UDP协议更简单,更容易复现BUG),在nginx.conf中配置每秒最大上传10个字节:
1 | proxy_upload_rate 10; |
客户端先发送10字节,服务器接收到后(用回包触发)客户端立刻再次发送10字节,预期服务器将在1秒后收到第2个报文,但实际上服务器有可能立刻收到报文,即proxy_upload_rate未生效或者不可控!一旦配置项处于不可解释的状态,这对于严谨的应用场景是不可接受的。而这个现象的原因,本质上是目前Nginx实现机制所致,接下来我会基于1.21版本的源码上解释其原理。
基于字节的限速实现原理
首先,我们要明确上例属于Nginx中的哪种限速。由于Nginx使用了内核协议栈,因此Nginx既不能对Packet级别的报文、也不能对TCP连接建立进行限速,而是只能在用户态基于调用socket编程API的时机,在字节转发速率、应用层协议的HTTP请求上(如官方的limit_req)做限制。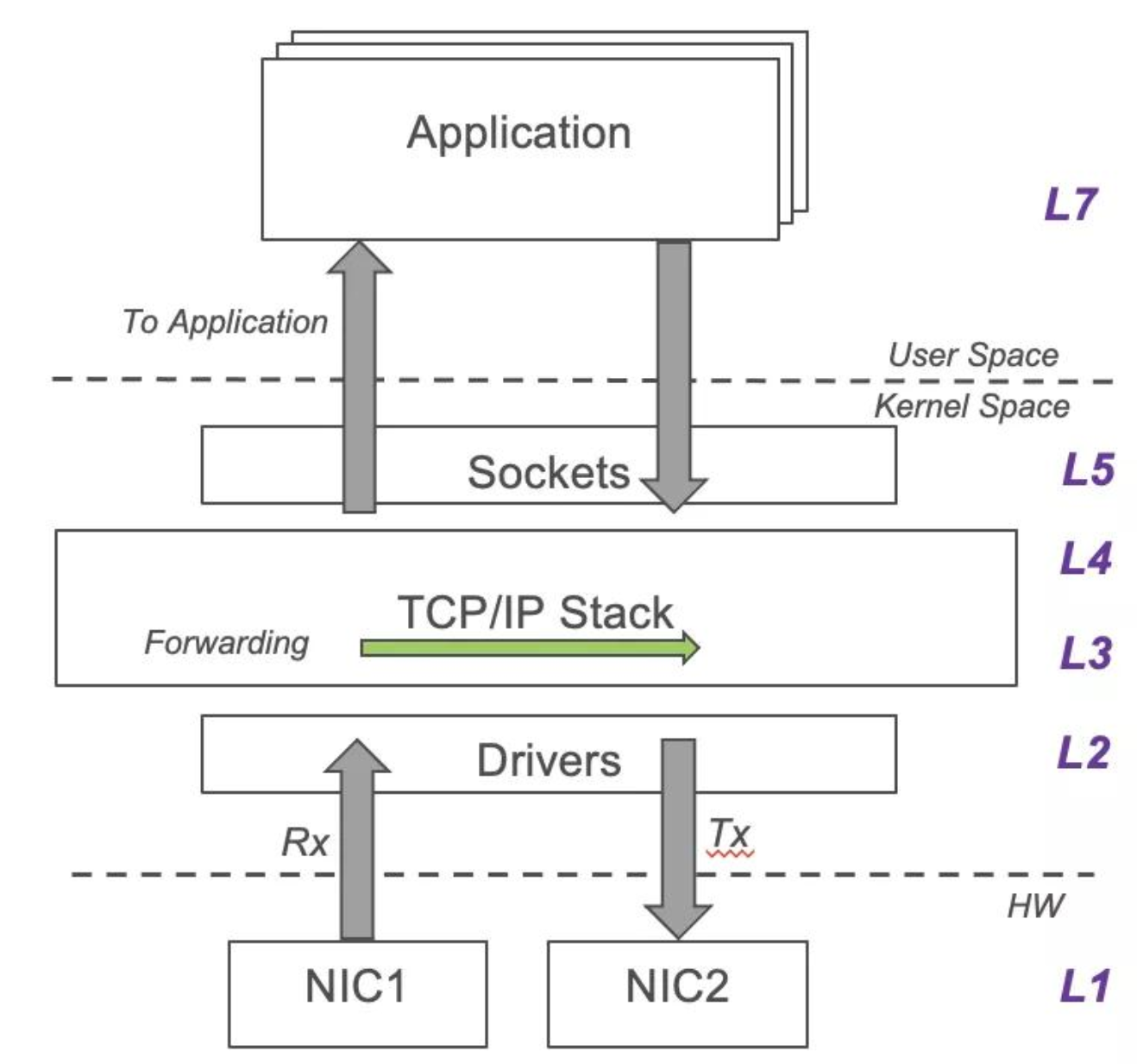
对于TCP协议的限速,当限速低于当前TCP连接的传输速率时,是通过零通告窗口来降低传输速率的。其具体作用原理为:作为接收端的Nginx所在服务器上,会有一个接收缓冲区,比如Linux中的tcp_rmem:
1 | net.ipv4.tcp_rmem = 4096 131072 6291456 |
tcp_rmem由TCP滑动窗口和socket读缓冲区共用,当Nginx在Epoll返回“可读”IO事件时,却不去读取socket数据,那么,当tcp_rmem被接收到的数据占满后,接收滑动窗口就会变为0,此时TCP连接的对端就会收到零窗口通知,进而停止发送数据,如下图所示: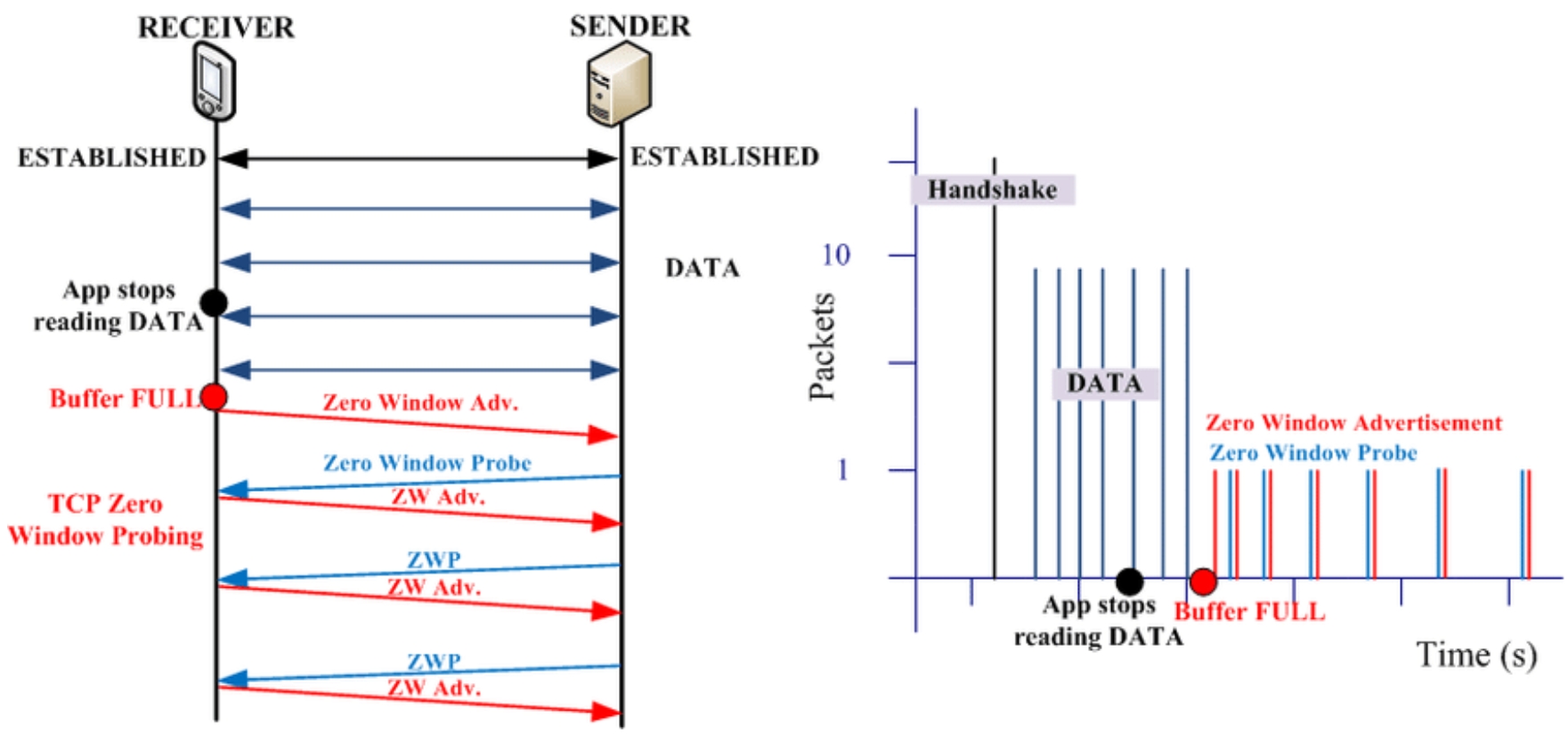
UDP协议与之类似,只不过因为没有重传机制,新收到的UDP报文会被直接丢弃。
对于字节转发速率的限制,Nginx正是通过上述机制生效的。无论是四层的proxy_upload_rate和proxy_download_rate,或者是七层的limit_rate,Nginx都是基于每秒转发字节数进行限速的,区别只在于,四层的2个指令都是在socket接收时生效,而七层则在socket发送到下游客户端(单向)时生效(这里并不基于TCP滑动窗口生效,因为Nginx只需保证降低发送HTTP响应的速率即可达到设计目标)。
下图是我以STREAM四层为例,画出的限速流程示意图: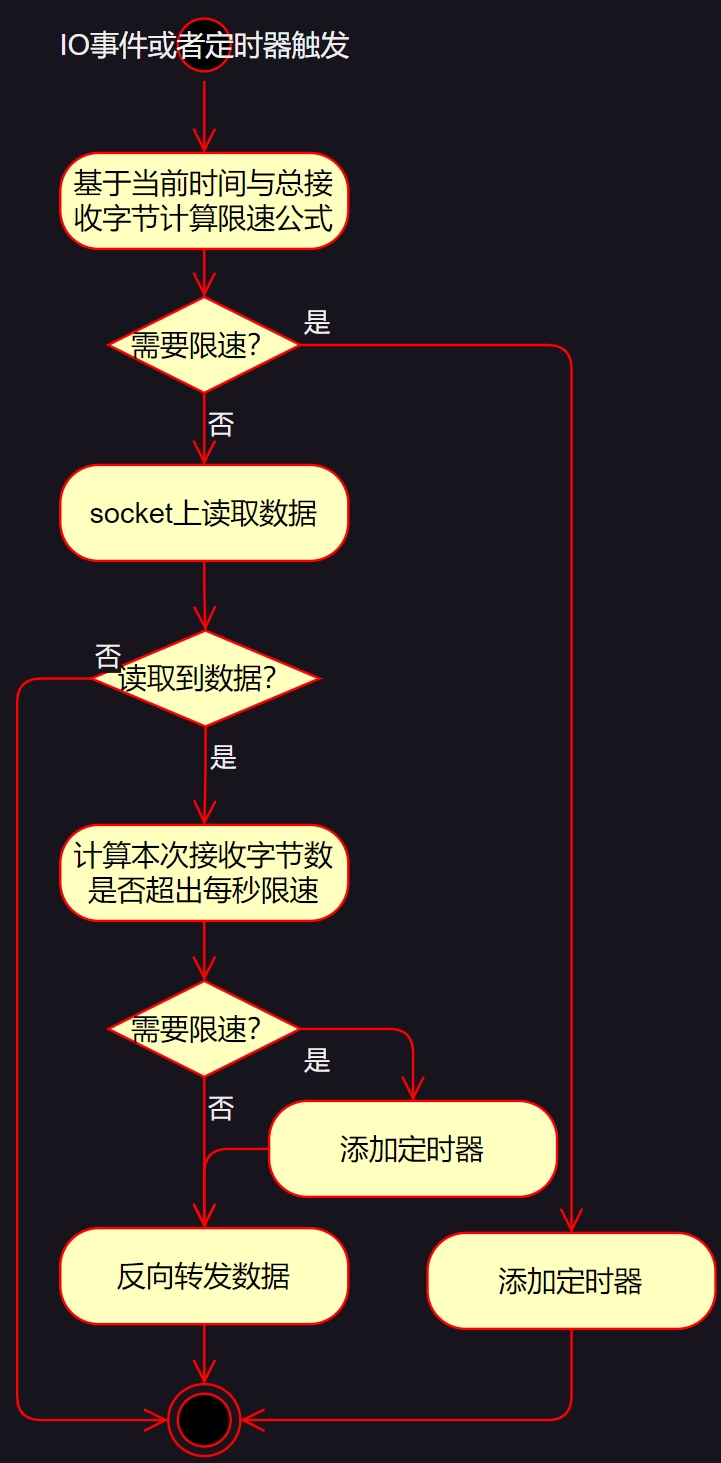
可以看到,在执行socket.read函数前会先计算一次限速公式,如果已经达到限速阈值,则根据计算出的等待时间添加定时器退出,此后就有可能出现TCP零窗口或者UDP报文丢弃;反之,才会将socket缓冲区中的数据拷贝到用户态转发。当然,在接收完数据后,还会做一次限速计算,此操作不影响本次数据的转发,只影响当前事件下是否会连续多次读取socket缓冲区。
开篇提到的限速失效问题关键就在于图中的限速公式。
Nginx的限速计算公式
先来看Nginx计算限速的关键代码,它在ngx_stream_proxy_module.c文件的ngx_stream_proxy_process函数中:
1 | if (limit_rate) { |
这个公式同时适用于上、下游的数据转发,当从下游客户端转发数据时,limit_rate值为nginx.conf配置文件的proxy_upload_rate指令,而从上游服务器转发数据时,limit_rate值则为配置文件的proxy_download_rate指令,而received指针指向已接收到的字节总数:
1 | if (from_upstream) { |
这个公式的设计思想是:如果ngx_time()当前时间与u->start_sec请求处理的起始时间的时间差内,转发的字节数received超出了limit_rate限制,就要立刻停止转发数据,其中暂停的时间是delay毫秒。虽然这个公式由STREAM四层使用,但HTTP七层也差不多,参见ngx_http_write_filter_module.c文件:
1 | if (r->limit_rate) { |
为了方便理解,我们继续以四层代码为例说明问题。当应该限速时,公式返回的limit变量就会大于0,而本文开头提到的测试场景,第2秒发送10字节时,*received的值肯定是10(第1秒转发),而ngx_time() - u->start_sec预期为1,所以limit的值预期为10*(1+1)-10,也就是10,进而delay值应为1秒才对。但实测结果却是有很大概率limit为0,导致Nginx没有限速。这是什么原因呢?
Nginx的时间更新方式
其实公式中的“变量”只可能是时间,毕竟limit_rate是配置文件中的指令,*received是已转发字节,这两者都不可能出错。所以,问题肯定出在u->start_sec或者ngx_time()的精准度上!前者u->start_sec的赋值很简单,参见ngx_stream_proxy_handler函数:
1 | static void |
当Nginx接收到下游客户端的数据,准备向上游服务器建立会话连接时,u->start_sec就被初始化为当前时间。再来看ngx_time函数是如何返回系统时间的:
1 | extern volatile ngx_time_t *ngx_cached_time; |
Nginx在新版本实现中为了优化性能,使用了缓存时间ngx_cached_time(即使调用ngx_timeofday函数返回的也是缓存时间),这带来了2个问题:
- ngx_time函数只取了秒,直接舍弃了毫秒精度(连四舍五入也没有考虑);
- ngx_cached_time的更新频率必然影响限速的时间精度。
本文开头问题与上述二者都有关系。忽略毫秒必然带来最大1秒的时间误差,而ngx_cached_time的更新频率会在此基础上放大ngx_time() - u->start_sec的误差,再来看下ngx_cached_time是如何更新的。
ngx_time_update函数负责更新ngx_cached_time,在谈其调用频率之前,先来看看它在多线程上的锁优化设计,这也有微小的时间精度降低:
1 |
|
Nginx支持多线程(虽然用得不多),因此为了减少加锁操作,Nginx使用了含有64个元素的数组cached_time循环复用保存时间,这样读时间时就省去了加锁操作,只在更新时才会加锁并通过变更slot的值移动循环数组:
1 |
|
ngx_time_update调用完成后,ngx_cached_time就会保存最新的时间。
再来看ngx_time_update函数的调用时机,这里主要参见Linux epoll多路复用机制中的ngx_epoll_process_events函数(这是更新时间的固定代码段):
1 | static ngx_int_t |
可见,每处理一批IO事件时,只要flags参数中携带了NGX_UPDATE_TIME标志,就会更新时间。那么,究竟何时会携带NGX_UPDATE_TIME标志位呢?这里要参见worker进程中循环调用的ngx_process_events_and_timers函数:
1 | void |
这里又多出了一个ngx_timer_resolution,这又是什么鬼?从官方文档中可以看到:
1 | Syntax: timer_resolution interval; |
timer_resolution是用于降低时间更新频率的。当然,默认情况下我们并不会配置timer_resolution,此时每批Epoll IO事件都会更新一次时间。
到这里,终于可以彻底回答本文开头的问题了。虽然Nginx的限速公式没有问题,但是Nginx时间精度却有2个问题,导致公式中的时间差ngx_time() - u->start_sec存在秒级的计算误差:
1、在系统不繁忙时,舍弃毫秒会导致最大1秒的误差;
2、时间更新频率则受到timer_resolution指令、epoll事件的批次数量、锁优化设计下的时间数组更新误差、worker进程的延迟调度等因素综合影响。
所以,我们在验证或者设计测试场景时,需要将上述2个因素都纳入考虑。同时,在Nginx更新版本时,综合评估Nginx源码设计的变动,就能更准确的掌握限速的要理。