负载均衡是Nginx的核心应用场景,本文将介绍官方提供的5种负载均衡算法及其实现细节。
Nginx提供的Scalability,主要由复制扩展(AKF X轴)和用户数据扩展(AKF Z轴)组成。所谓复制扩展,是指上游Server进程是完全相同的,因此可以采用最少连接数、Round Robin轮询、随机选择等算法来分发流量。所谓用户数据扩展,是指每个上游Server只处理特定用户的请求,对这种场景Nginx提供了支持权重的哈希算法,以及支持虚拟节点的一致性哈希算法。
当上游集群规模巨大时,我们必须了解这些算法的细节,才能有效地均衡负载。比如,当上游server出错时,Weight权重会动态调整吗?调整策略又是什么?如果算法选出的上游server达到了max_fails限制的失败次数,或者max_conns限制的最大并发连接数,那么又该如何重新选择新路由呢?
再比如,为了减少宕机、扩容时受影响的Key规模,同时让CRC32哈希值分布更均衡,Nginx为每个Weight权重配置了160个虚拟节点,为什么是这个数字?一致性哈希算法执行的时间复杂度又是多少呢?
这一讲我将深入分析Nginx的负载均衡算法,同时围绕ngx_http_upstream_rr_peer_s这个核心数据结构,探讨这些HTTP负载均衡模块到底是怎样工作的。同时,本文也是Nginx开源社区基础培训系列课程第二季,即7月16日晚第2次直播课的文字总结。
RoundRobin权重的实现算法
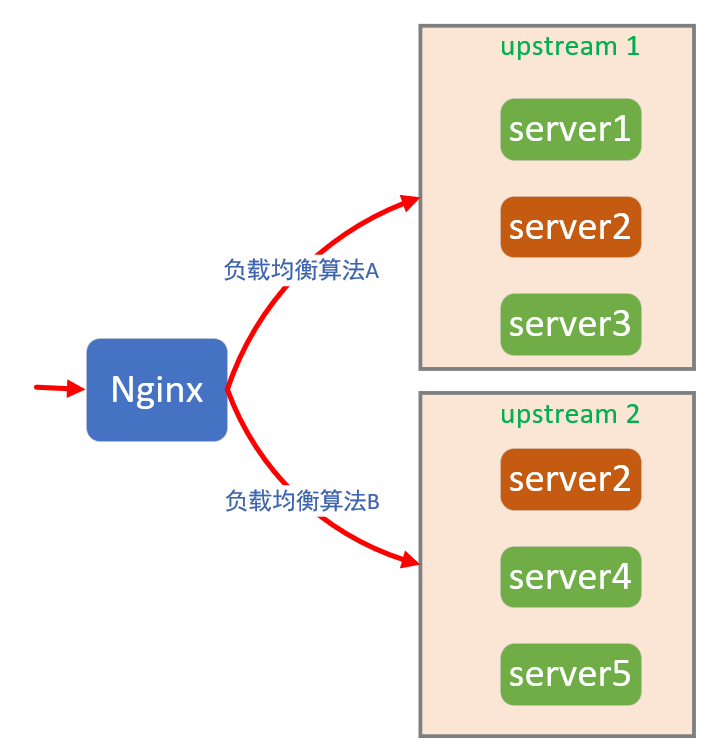
在Nginx中,上游服务可以通过server指令声明其IP地址或者域名,并通过upstream块指令定义为一组。这一组server中,将使用同一种负载均衡算法,从请求信息(比如HTTP Header或者IP Header)或者上游服务状态(比如TCP并发连接数)中计算出请求的路由:
如果上游服务器是异构的,例如上图中server 1、3、4、5都是2核4G的服务器,而server 2则是8核16G,那么既可以在server 2上部署多个不同的服务,并把它配置到多个usptream组中,也可以通过server指令后的weight选项,设置算法权重:
1 | upstream rrBackend { |
在上面这段配置指令中,并没有显式指定负载均衡算法,此时将使用Nginx框架唯一自带的RoundRobin轮询算法。顾名思义,它将按照server在upstream配置块中的位置,有序访问上游服务。需要注意,加入weight权重后,Nginx并不会依照字面次序访问上游服务。仍然以上述配置为例,你可能认为Nginx应当这么访问:8001、8002、8002、8003、8003、8003(我在本机上启动了这3个HTTP端口,充当上游server,这样验证成本更低),但事实上,Nginx却是按照这个顺序访问的:8003、8002、8003、8001、8002、8003,为什么会这样呢?实际上这是为了动态权重的实现而设计的。我们先从实现层面谈起。
Nginx为每个server设置了2个访问状态:
1 | struct ngx_http_upstream_rr_peer_s { |
其中current_weight初始化为0,而effective_weight就是动态权重,它被初始化为server指令后的weight权重。我们先忽略转发失败的场景,此时RoundRobin算法可以简化为4步:
- 遍历upstream组中的所有server,将current_weight的值增加effective_weight;
- 将全部的权重值相加得到total;
- 选择current_weight最大的server;
- 将这个选中server的current_weight减去total值。
这样,前6次的运算结果就如下表所示:
| current_weight | current_weight加effective_weight | total | 选中server | current_weight |
|---|---|---|---|---|
| [0,0,0] | [1,2,3] | 6 | 8003 | [1,2,-3] |
| [1,2,-3] | [2,4,0] | 6 | 8002 | [2,-2,0] |
| [2,-2,0] | [3,0,3] | 6 | 8003 | [3,0,-3] |
| [3,0,-3] | [4,2,0] | 6 | 8001 | [-2,2,0] |
| [-2,2,0] | [-1,4,3] | 6 | 8002 | [-1,-2,3] |
| [-1,-2,3] | [0,0,6] | 6 | 8003 | [0,0,0] |
| [0,0,0] | [1,2,3] | 6 | 8003 | [1,2,-3] |
由于总权重为6(1+2+3),所以每6次转发后就是一个新的轮回。我再把简化的RoundRobin源代码列在下方,你可以对照理解:
1 | ngx_http_upstream_rr_peer_t* best = NULL; |
可以看到,这段代码只做一遍循环就完成了server选择,执行效率很高。
网络错误该如何处理?
在上例中我们假定不会转发失败,所以effective_weight是不变的。但现实中分布式系统出错才是常态,接下来我们看看RoundRobin算法是怎样处理错误的。
在server指令后,可以加入max_fails和fail_timeout选项,它们共同对转发失败的次数加以限制:
- 在fail_timeout秒内(默认为10秒),每当转发失败,server的权重都会适当调低(通过effective_weight实现);
- 如果转发失败次数达到了max_fails次,则接下来的fail_timeout秒内不再向该server转发任何请求;
- 在等待fail_timeout秒的空窗期后,server将会基于最低权重执行算法,尝试转发请求;
- 每成功转发1次权重加1,直到恢复至weight配置。
这就是动态权重发挥作用的机制,它不只对RoundRobin算法有效,对于最少连接数、一致性哈希算法同样有效。接下来我们再从实现层面上回顾下这一流程,加深你对动态权重的理解。Nginx为这一功能准备了6个状态变量:
1 | struct ngx_http_upstream_rr_peer_s { |
其中,weight、max_fails、fail_timeout都是server指令后的选项,它们是固定不变的。fails是窗口期的转发失败次数,accessed表示最近一次转发失败时间,而checked则是最近一次转发时间(无论成功或者失败)。
这样,当访问上游server失败时,将会把accessed和checked置为当前时间,并将fails次数加1:
1 | peer->fails++; |
如果max_fails功能没有关闭(0表示关闭,默认值是1),就会通过effective_weight适当降低权重:
1 | if (peer->max_fails) { |
当执行负载均衡算法时,如果在fail_timeout秒内连续失败了max_fails次,则不再访问该server:
1 | if (peer->max_fails |
在过了fail_timeout秒的空窗期后,一旦算法再次选择了该server,就会将checked重置为当前时间:
1 | if (now - best->checked > best->fail_timeout) { |
一旦最终转发请求成功,就会通过accessed将fails失败次数清零:
1 | if (peer->accessed < peer->checked) { |
注意,此时effective_weight还需要通过不断的成功来缓慢恢复权重:
1 | if (peer->effective_weight < peer->weight) { |
RoundRobin算法还能控制并发连接数,你可以通过server指令后的max_conns选项设置(默认为0表示不加限制)。它的实现原理非常简单,这里不再介绍。
可见,RoundRobin算法可以柔性恢复转发错误。如果上游Server进程是复制扩展的(处理的数据相同),那么RoundRobin就是最简单有效的负载均衡算法。
最少连接数与随机选择算法
前文之所以要详尽的介绍RoundRobin权重、错误恢复、并发连接限制等功能,是因为Nginx中几乎所有负载均衡算法,都在一定程度上继承了上述机制。接下来我们分析与RoundRobin极为相似的Least Conn和Random算法,它们皆处理沿AKF X轴扩展的场景。
首先来看Least Conn最少连接数算法。多数场景下,并发TCP连接最少的服务器负载最轻,因此ngx_http_upstream_least_conn_module模块会选择连接最少的server转发请求。只需要在upstream中加入least_conn指令,就可以开启最少连接数算法:
1 | upstream { |
它的实现非常简单,在符合max_fails、fail_timeout失败次数约束、max_conns并发连接数约束下,取当前并发连接数与权重相乘后最小的server即可:
1 | if (best == NULL |
如果存在不只1个的最少连接server,将对这些上游server继续执行RoundRobin算法。
其次,我们再来看Random随机选择算法。如前文所述,RoundRobin轮询算法是有规律的,当我们需要完全随机的访问上游server时,就可以选择Random算法,它的开启方式非常简单,在upstream中加入random指令即可:
1 | upstream rrBackend { |
此时,Nginx会建立含有3个元素的有序数组,分别对应3个server,其值为权重的累加值,如下所示:
1:server1 | 3(1+2):server2 | 6(1+2+3):server3
——- | ——- | ——-
执行随机算法时,首先取小于total_weight(即6)的随机数:
1 | ngx_uint_t x = ngx_random() % peers->total_weight; |
接着,基于二分法遍历有序数组,找到下标x对应的上游server:
1 | ngx_uint_t i = 0; |
注意,随机选择出的server很有可能并不满足max_fails、fail_timeout失败次数的约束,或者不满足max_conns并发连接数约束。对于同一个请求,如果连续20次的随机选择都没有找到合适的server,那么Random算法将会退化为RoundRobin算法选择server。
事实上,Random算法还有一个功能,你可以在random指令后添加two least_conn选项,这样算法将会随机找出2个server,再选择并发连接数最少的那1个:
1 | upstream rrBackend { |
官方提供的RoundRobin、最少连接数、随机选择这3个算法,只适用于无差别的上游服务。当上游server只处理特定范围的请求时,可以使用ip_hash、hash以及hash consistent这三种算法。
哈希算法的问题
复制扩展无法解决数据增长问题,这样当业务增长到某一阶段,以致上游server无法将高频访问数据全部放于内存中时,性能便会一落千丈。Nginx通过ngx_http_upstream_ip_hash_module、ngx_http_upstream_hash_module这两个模块,实现了哈希与一致性哈希算法,它们可以限制每个上游server处理的数据量,以此提升上游server的性能。我们先来看ip_hash算法。
每个IP报文头部都含有源IP地址,它标识了唯一的客户端。因此,将IP地址依据字符串哈希函数转换为32位的整数,再对server总数取模,就可以将客户端与上游server的访问关系固定下来。
它的实现非常简单,包括以下3步:
将IP地址这个字符串转化为哈希值,代码如下所示:
ngx_uint_t hash = 89; for (i = 0; i < (ngx_uint_t) iphp->addrlen; i++) { hash = (hash * 113 + iphp->addr[i]) % 6271; }接着,基于所有上游server的权重和,缩小哈希值范围:
ngx_uint_t w = hash % iphp->rrp.peers->total_weight;最后,通过遍历所有server的权重,选取上游server:
1
2
3
4while (w >= peer->weight) {
w -= peer->weight;
peer = peer->next;
}可见,相对于采用二分查找的Random算法,古老的ip_hash性能有所下降(时间复杂度从O(logN)降到O(N)),在server非常多时性能不够理想。
实际上,ip_hash还有一个很糟糕的问题,就是对于IPv4地址,它会忽略最后1个字节的值。比如若IP地址为AAA.BBB.CCC.DDD,那么ip_hash只会使用AAA.BBB.CCC来求取哈希值,相关代码如下所示:
1 | case AF_INET: |
对于后出现的IPv6地址,将会使用全部16个字节的地址。为了向前兼容,ip_hash模块很难修改掉IPv4地址的这个Bug。此时,你可以使用更新的hash指令来解决,它可以对Nginx变量(也接受变量与字符串的组合)取哈希值:
1 | upstream { |
hash模块会使用CRC32函数,对变量求出32位的哈希值,之后执行与ip_hash相同的算法。
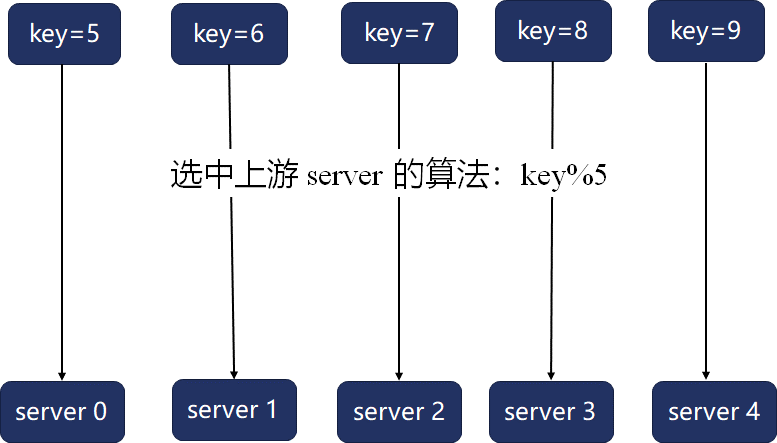
哈希算法最大的问题在于,当server数量、权重发生变化时,映射函数就会变化,很容易导致映射关系大幅变动。比如,当上游server数量为5时,关键字与上游server的映射如下所示:
一旦server4宕机,这5个关键字的映射关系就会全部变动: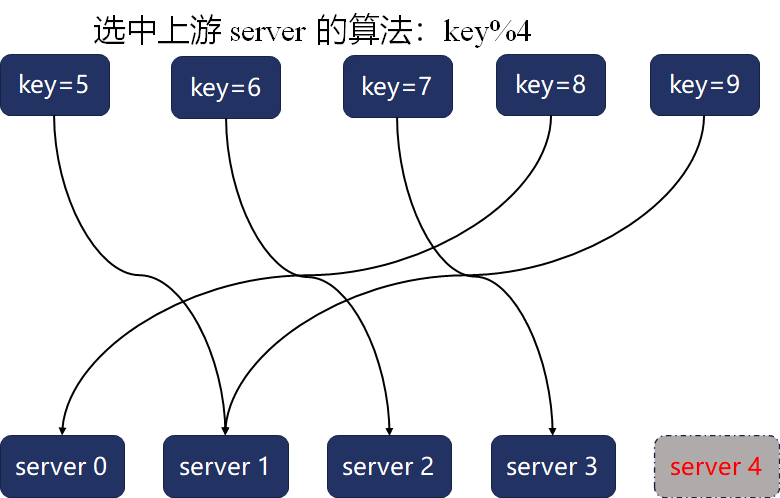
如果上游server为数据建立了缓存,那么此时会导致这5个关键字对应的缓存全部失效。
一致性哈希算法是怎样实现的?
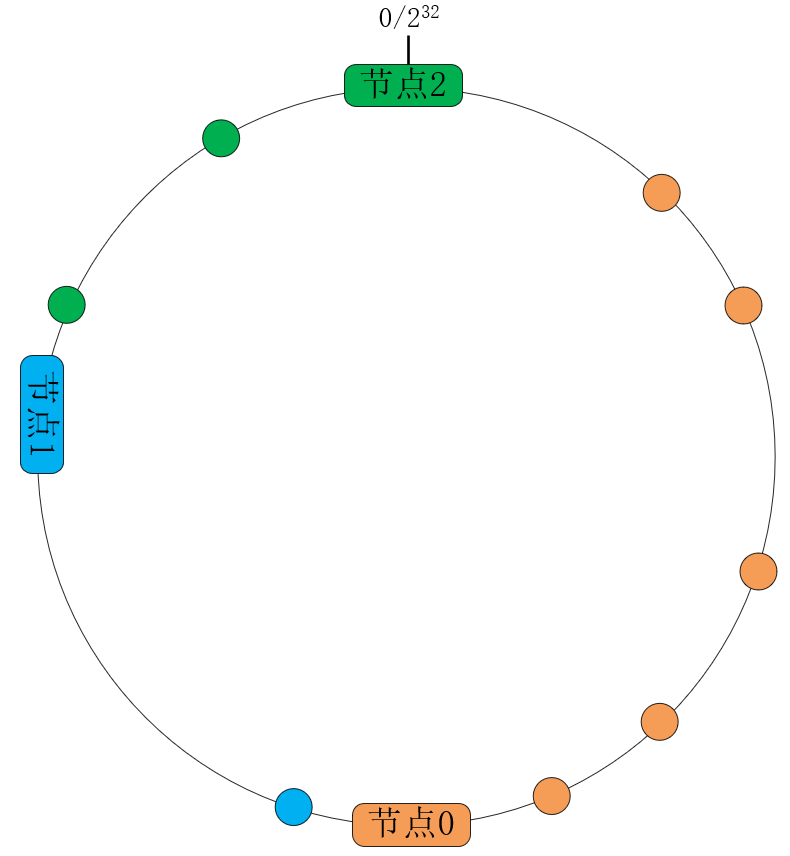
一致性哈希算法将哈希算法中的函数映射,改为32位数字构成的环映射,大幅降低了server变动时受影响的关键字数量。如下图所示,Nginx将关键字(hash指令后的变量)基于CRC32函数转换为无符号的32位整数,其中232与0相接构成了一个环:
这样,3个server将会基于weight权重,各自负责环中的一段弧线,划分了处理关键字的范围。当扩容或者宕机时,只会影响相邻server节点上的关键字。
当然,这样还是有2个问题:
- 当节点1宕机时,它负责的所有请求都被映射到了节点2,这样节点2可能会抗不住压力继续宕机,进而引发雪崩效应。扩容时也一样,当增加节点3时,只是分流了节点2上的请求,这对节点0、节点1完全没有帮助。
- 如果server只是基于权重划分哈希环,那么很难保证全部关键字均衡地落进每个server上。
解决这2个问题的方案,就是在哈希环上,增加一层二次映射的虚拟节点环。这样,二次哈希既可以让数据分布更均衡,也可以由全体server共同分担宕机压力,享受扩容带来的收益。
虚拟节点数量越多,分布会越均衡。然而,在有序的哈希环上选择server,最快的方法也只是二分查找法,它的时间复杂度是O(logN),因此,虚拟节点数还是得控制在一个范围内。通常,每个真实节点对应的虚拟节点数在100到200之间,而Nginx选择为每个权重分配160个虚拟节点。
下面我们看下Nginx是如何实现一致性哈希算法的。对于哈希环上的每个虚拟节点,Nginx都会分配1个ngx_http_upstream_chash_point_t结构体表示:
1 | typedef struct { |
其中,hash是二次哈希映射后的值,server则指向真实的上游服务。这些虚拟节点环会以数组的形式放在ngx_http_upstream_chash_points_t结构体中:
1 | typedef struct { |
其中,number成员保存了虚拟节点的总数量,而point则是虚拟节点环的首地址。
构建虚拟节点环的初始化代码如下所示:
1 | ngx_uint_t npoints = peer->weight * 160; //每个权重赋予160个虚拟节点 |
当用户请求到达时,会首先基于Nginx变量生成CRC32哈希值,接着采用二分查找法,在O(logN)时间复杂度下找到对应的真实server:
1 | ngx_http_upstream_chash_point_t * point = &points->point[0]; //环上第1个虚拟节点 |
如果选出的server由于失败次数、并发连接数达到限制后,将会采用闭散列函数的方案,尝试选择相邻哈希桶上的server。另外,如果连续选出的20个server都不能使用,一致性哈希算法将会回退到RoundRobin算法。
小结
最后对本文内容做个总结。
为异构服务器设置Weight权重后,Nginx还为转发失败提供了动态权重功能。其中,每失败1次,动态权重会下降weight/max_fails,在fail_timeout时间窗口内失败次数达到max_fails后,server将会冷却fail_timeout秒,之后权重会缓慢恢复。动态权重对于RoundRobin、一致性哈希、最少连接数算法都有效。
当哈希、随机选择算法连续20次计算出的server都不可用,它们会退化为RoundRobin算法。当一致性哈希算法计算出的server不可用时,则会顺序向后寻找相邻哈希桶上的server。同样连续20次失败后,也会退化为RoundRobin算法。因此,理解Nginx框架自带的RoundRobin算法,对于学习负载均衡算法至关重要。
Nginx为一致性哈希算法上的每个权重分配了160个虚拟节点,这个数字既照顾到了分布均衡性及流量压力的分散,也照顾到了算法的执行效率,毕竟二分查找法的时间复杂度是O(logN)。
下一篇,我们将讨论Nginx如何向客户端隐藏应用层错误。