前端与后端的思维专注点很不相同,前端聚焦在如何把内容以可视化的方式展现给用户,后端聚焦在如何利用IT基础设施实现业务逻辑。所以前端参与后端开发时(全栈工程师必备!)首先需要理解后端会做哪些事,其次才是如何才能做好这些事。 所谓“利用IT基础设施实现业务逻辑”,意味着以下几个概念:
IT基础设施有哪些?
数据库一定是最重要的,这里特指关系数据库,例如mysql。因为前端所用的数据库往往非常简单,浏览器或者APP毕竟只服务于一位用户,而后端的数据库需要服务于全部用户,这不是一个量级。在现实世界中,一旦量级发生改变,需要用到的技术就完全不一样了。数据库的基本操作ACID、事务、关联查询、索引都是完成业务逻辑的必备品。 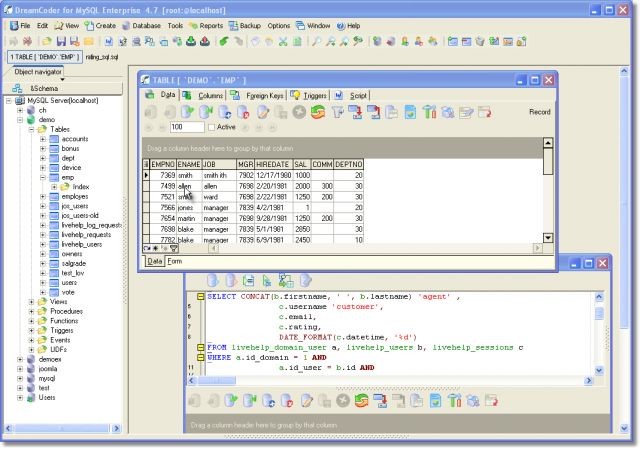 缓存也是前端必须理解的概念。后端可以直接操作SATA磁盘,SSD磁盘,内存等不同的存储介质,而这些介质的存取速度差异巨大。CPU操作L1和L2缓存只有3个纳秒以内,到了L3缓存(可以以MB为单位计量了)就得10纳秒以上了,而到了内存就得100纳秒以上,通过网卡访问远端则需要数百微秒,访问机械硬盘则要几十毫秒。为了能够让用户的请求尽快获得响应,必须使用缓存。很少的场景下才会直接编写缓存,通常后端都在使用的缓存服务包括redis、memcached等,其中前者使用更多。
缓存也是前端必须理解的概念。后端可以直接操作SATA磁盘,SSD磁盘,内存等不同的存储介质,而这些介质的存取速度差异巨大。CPU操作L1和L2缓存只有3个纳秒以内,到了L3缓存(可以以MB为单位计量了)就得10纳秒以上了,而到了内存就得100纳秒以上,通过网卡访问远端则需要数百微秒,访问机械硬盘则要几十毫秒。为了能够让用户的请求尽快获得响应,必须使用缓存。很少的场景下才会直接编写缓存,通常后端都在使用的缓存服务包括redis、memcached等,其中前者使用更多。
如何正确的分析业务逻辑?
UML图是一个非常好的手段!类图、时序图、状态图可以帮助后端理清先做什么、再做什么、不会漏掉什么。这是因为后端的程序需要整年的运行不能宕机,而前端是没有这种要求的。因此,后端必须全面的考虑各种异常情况,防止一个用户(请求)引起的意外把整个服务宕机,影响了全部用户。 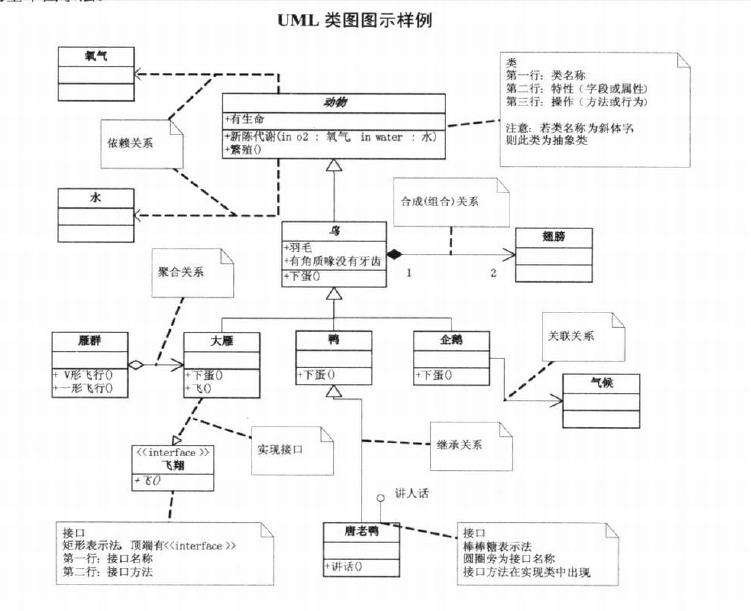
业务逻辑如何与IT设施结合?
了解MVC模型!前端有许多模型,例如MVVM等,这些名词不重要,因为它们的关注点各不相同。对于后端,通常M意味着关系数据库,所以后端的WEB框架一定围绕着M进行。我们分析任何一个WEB框架,一定先要看它的数据库模型,即如何将数据库中的表、行映射到编程语言中。另一方面,HTTP协议有许多特性,它会导致MVC框架试图以此解耦,将URL的配置与业务处理代码分开。最后,WEB框架由于处理场景的复杂,通常以可插拔的方式将许多插件串行的组合起来处理一个请求。前端在学习WEB框架时,把握这三点即可快速掌握。 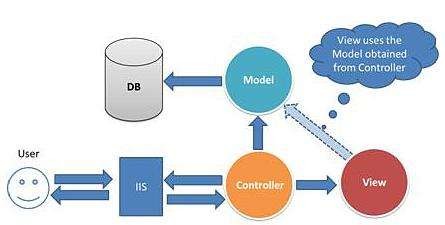 前端做后端时最容易犯2个错误:
前端做后端时最容易犯2个错误:
日志打得很少
后端的复杂场景会导致bug难以复现(相比前端更难),且一个应用服务可能跑在多个服务器上,所以error、info、debug等级日志的输出显得尤为重要!没有日志,问题很难定位!
资源没有即用即放!
因为服务是7*24小时运行的,所以一点点资源泄露(如打开了句柄却未关闭)都会被时间放大!最后导致严重后果。 后端的代码如何更高效?答案一定是算法! 好的算法在我看来就是3点:
- 不做重复的事;
- 充分利用已知信息或者中间计算结果;
- 充分利用IT基础设施的特性。比如多核、CPU亲和性、存储介质的性价比、网络报文的收发等。
为了达到这一点,我们必须学习:
- 算法复杂度;
- 分而治之的思想,这可能是所有算法思想中最有用的了;
- 计算机体系的特点,如CPU架构、网络通讯成本等;
- 常用数据结构,如树、哈希表、图等。
本文出现的原因是团队中有前端同事想在后端试试水,我当然非常欢迎,于是尽量从我对前端的理解上阐述后端开发的要点,或者更准确的说,是后端WEB应用开发工程师的开发要点。全栈工程师的要求高得多,这里虽然有些标题党嫌疑,但好在标明了基础版,进阶版在好好谈谈前端转全栈工程师的其他要求。