Raft是分布式环境下的一致性算法,它通过少数服从多数的选举来维持集群内数据的一致性。它与RBFT算法名称有点像,然而Raft算法里不能存在拜占庭节点,而RBFT则能容忍BFT节点的存在。Raft非常类似于paxos协议(参见我的这篇文章《paxos算法如何容错的–讲述五虎将的实践》),然而它比paxos协议好理解许多(因为paxos协议难以具体实现,所以zookeeper参考paxos实现了它自己的Zab算法)。同样,Raft有一个用GO语言实现的etcd服务,它的功能与Zookeeper相同,在容器操作系统CoreOS作为核心组件被使用。 本文先从算法整体上说明其特点,再细说其实现。为方便大家理解,本文还是以图为主,没有过多涉及算法的细节。Raft易理解易实现,是我们入门分布式一致性算法的捷径!
1.算法易被理解
Raft协议的性能并不比paxos的各种实现更高,它的优点主要在于协议的可理解性好,且非常具备可操作性,很容易照着协议就可以实现出稳定、健壮的算法。论文作者在斯坦福和加州大学做过测试,对本科及研究生分别学习paxos和Raft协议课程后测验,在总分60分的测试里其得分如下图所示: 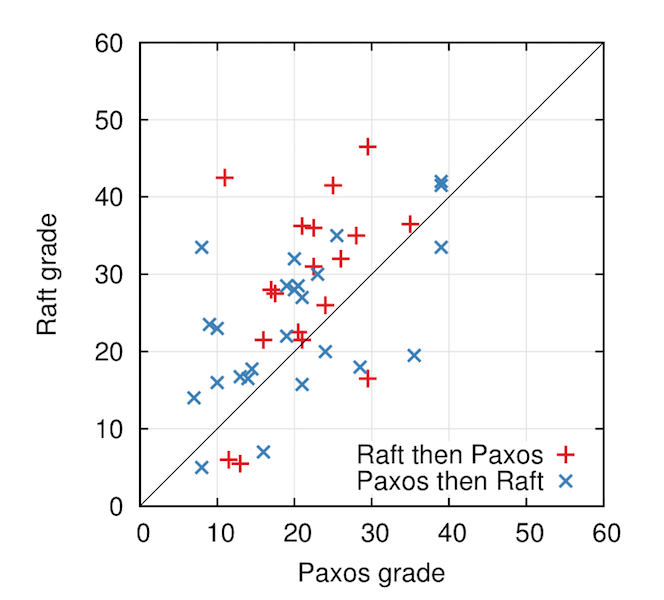 从上图可见,Raft协议的得分(平均25.7)明显高于paxos(平均20.8)。我相信学习过paxos算法的人都有心得:很辛苦的理解后,一段时间后就完全不记得细节了,至少我本人是如此。而Raft协议非常简单清爽,这个测试也很能反映问题。在测试后,作者还发起了一个调查问卷,询问学生这两个算法哪个更容易实现?哪个更容易理解?其答案如下图所示:
从上图可见,Raft协议的得分(平均25.7)明显高于paxos(平均20.8)。我相信学习过paxos算法的人都有心得:很辛苦的理解后,一段时间后就完全不记得细节了,至少我本人是如此。而Raft协议非常简单清爽,这个测试也很能反映问题。在测试后,作者还发起了一个调查问卷,询问学生这两个算法哪个更容易实现?哪个更容易理解?其答案如下图所示: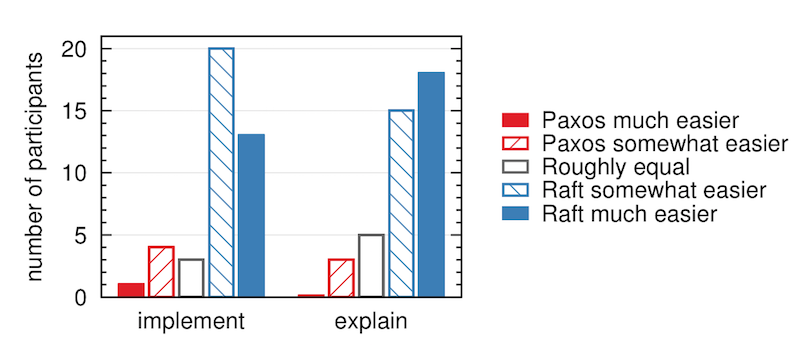 可见,这个带有主观性的调查问卷呈现压倒性优势:Raft是一个容易理解、容易实现的算法。
可见,这个带有主观性的调查问卷呈现压倒性优势:Raft是一个容易理解、容易实现的算法。
2.算法实现etcd的性能测试数据
Raft有很多语言的实现,包括C++、GO、Scala、Java等(详见https://raft.github.io/),但最有名的实现就是etcd了,它作为CoreOS生态的重要组件而闻名。我们可以通过etcd的性能数据看一看Raft算法的实际表现。
测试集群由3台服务器构成,其配置如下:
- Google Cloud Compute Engine
- 3 machines of 8 vCPUs + 16GB Memory + 50GB SSD
- 1 machine(client) of 16 vCPUs + 30GB Memory + 50GB SSD
- Ubuntu 17.04
- etcd 3.2.0, go 1.8.3
下面分别测试写和读的性能。在读性能数据中,Linearizable一致性高于Serializable,故性能稍差。其原始页面在这里:https://coreos.com/etcd/docs/latest/op-guide/performance.html。 事实上,在算法的正常运行中与paxos并无差异。而一旦leader宕机,从发现到重新选举出新leader、新leader开始工作的这段时间的长短,是影响性能的重要指标。下图中对5个节点构成的集群反复的让leader宕机,观察恢复的时间,其结果如下: 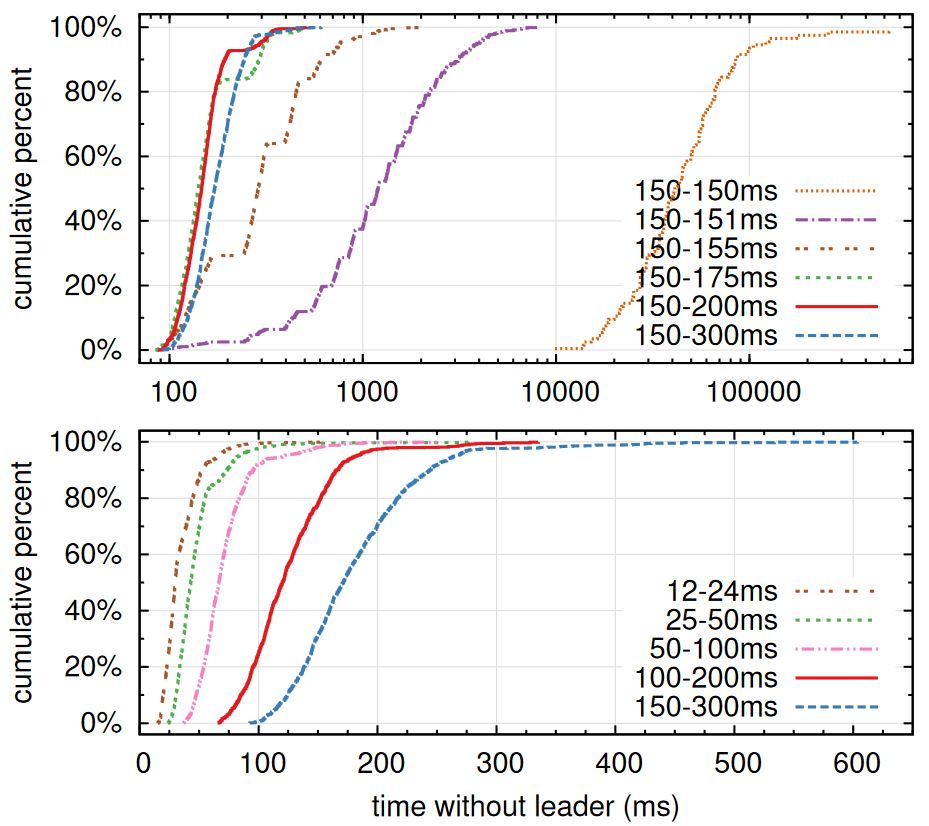 在上图中有以下几个关注点:
在上图中有以下几个关注点:
- 不同颜色及线条代表着follower的定时器。如在300ms内没有收到leader的心跳,则发起选举。其中150-300ms这样的数据表明,这5台follower的定时器分布在150ms到300ms之间,呈现随机化。而150-150ms表示没有随机化,所有节点的超时时间是一样的。
- 横坐标代表着发现到替换掉宕机leader开始服务的时间。数值的单位为毫秒。
- 纵坐标表示测试时间在全部测试数据中的比例。以上每条线都做了1000次试验(除150-150ms只试验了100次)。
上图表明,增加随机化后,可以大幅减少选举的平均用时。下面的图表明,通过降低最短的超时时间,也可以减少宕机时间。Raft推荐的时间为150-300ms。
3、Raft算法概述
复杂的问题可以通过分解为多个简单的子问题来解决,Raft正是如此(paxos很难分解)。Raft首先定义自己是一个key/value数据库。那么,请求就分为读和写。Raft将问题分解为以下几个要点:
- 集群里有一台为leader节点服务器,且读写请求都只能向该节点发送,以此保证一致性;
- 当集群内没有leader节点时,leader节点被多数节点选出来。比如集群有3个节点,那么2个节点同意的话,就可以选出1个作为leader;
- 除leader节点外,其他节点叫做follower追随者。leader节点向follower节点同步每条写请求;
因此Raft将一致性问题转换为leader的选举上,以及leader与follower之间的数据同步。我们先来谈leader与 follower之间的数据同步问题。每一次写请求会修改数据,读请求则不会,所以把leader收到的写请求当作一次操作日志记录下来,且同时把操作日志同步给所有的follower节点,而有一个最终状态数据库记录某一个key的最终值,如下图所示(事实上这与fabric区块链里,多条交易日志构成的世界状态数据库非常相似,详情请参见《区块链开源实现hyperledger fabric架构详解》): 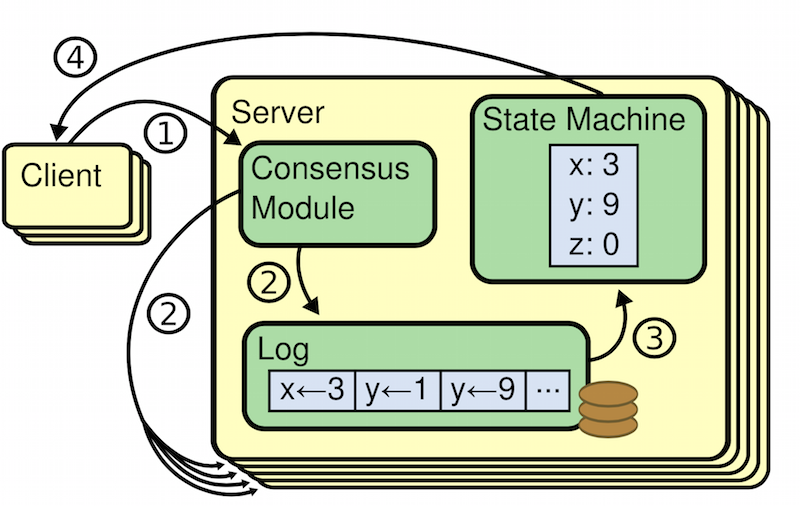 上图中其步骤含义如下:
上图中其步骤含义如下:
- leader收到写请求y=9,此时状态数据库是y=1;
- 将y=9这条日志追加到Log的末尾,同时将该条日志同步给其他follower;
- 当多数follower成功收到这条y=9的日志后,leader将状态数据库从y=1更新为y=9;
- 返回client表示y=9设置成功。
4、如何选举出leader
当一个集群刚启动时,所有的节点都是follower,follower只能被动的接收leader的消息并响应。此时经过一段时间若follower节点发现全集群没有leader,开始把自己作为leader的候选人向大家征询投票,此时该节点叫做Candidate候选人。若多数follower节点同意后,则升级为leader节点。而leader节点有义务定时心跳通知所有的 follower节点,使follower节点知道此时集群中的leader是谁。如下图所示: 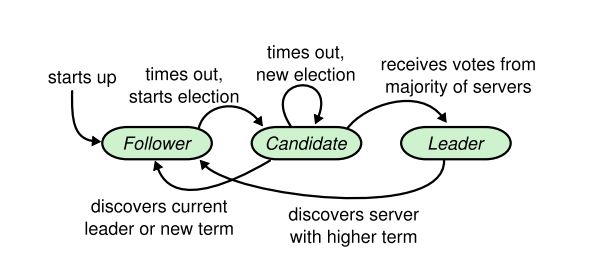 上图的状态变迁里,follower在一个随机定时器(例如150ms到300ms之间)内没有收到leader的心跳,则开始发起选举,而候选人就是自己,所以自己转化为Candidate,且自己首先投自己一票。若在投票未完成时,发现新的leader出现,则取消投票,由candidate转换为follower。 每次选举是一个任期,这个任期叫做term。每次任期有一个任期号,它是全局的、递增的,当网络中断时虽然会暂时不一致,但网络畅通后会很快同步,如下图所示:
上图的状态变迁里,follower在一个随机定时器(例如150ms到300ms之间)内没有收到leader的心跳,则开始发起选举,而候选人就是自己,所以自己转化为Candidate,且自己首先投自己一票。若在投票未完成时,发现新的leader出现,则取消投票,由candidate转换为follower。 每次选举是一个任期,这个任期叫做term。每次任期有一个任期号,它是全局的、递增的,当网络中断时虽然会暂时不一致,但网络畅通后会很快同步,如下图所示: 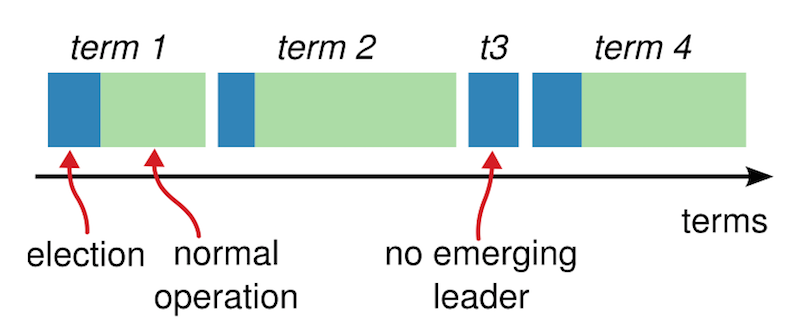 如上图中,蓝色是选举期,绿色是产生leader后。如果不出现意外,这个leader会一直当下云,所以term周期会很长。出现宕机或者网络波动时,重新选举于是出现term2。在term3时也可能一直选举不出新的leader,此时很可能多个candidate发起了投票,票数被平摊后谁也没拿到大多数(由于每台follower的定时器时间是随机的,因此该情况发生概率很小,且发生后也能很快回归正常)。于是会进入term4。
如上图中,蓝色是选举期,绿色是产生leader后。如果不出现意外,这个leader会一直当下云,所以term周期会很长。出现宕机或者网络波动时,重新选举于是出现term2。在term3时也可能一直选举不出新的leader,此时很可能多个candidate发起了投票,票数被平摊后谁也没拿到大多数(由于每台follower的定时器时间是随机的,因此该情况发生概率很小,且发生后也能很快回归正常)。于是会进入term4。
5、操作日志的同步
leader需要把写日志同步到大多数follower后才能更新状态数据库,并向client回复写成功。如果没有得到多数follower的成功应答,leader会重复发送这条日志更新请求。下图中有8条日志3个任期5个节点,每条日志里除记录了操作行为外还记录了当时的任期: 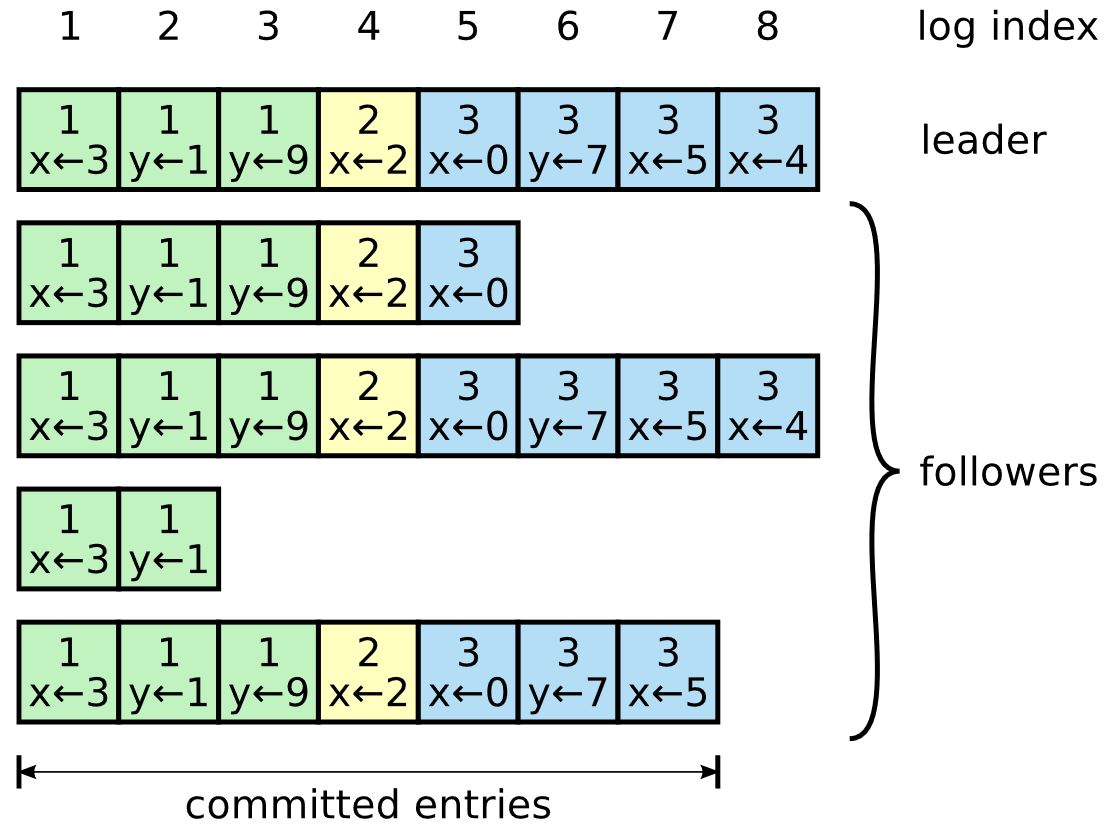 上图中,绿色是第一个任期,其中3条日志条目中第3条日志y=9没有被第4个节点接收到。黄色是第2个任期。绿色与黄色任期内,所有的日志皆被多数节点收到,因此都是写入状态数据库的,这些日志的状态都是commited已提交状态。蓝色是第3个任期,其第8条日志x=4没有被多数节点收到,因此该日志不是committed状态。 leader与 follower之间的日志也可能存在不一致的情况,follower或者少了一些日志,或者多了一些日志,如下图所示:
上图中,绿色是第一个任期,其中3条日志条目中第3条日志y=9没有被第4个节点接收到。黄色是第2个任期。绿色与黄色任期内,所有的日志皆被多数节点收到,因此都是写入状态数据库的,这些日志的状态都是commited已提交状态。蓝色是第3个任期,其第8条日志x=4没有被多数节点收到,因此该日志不是committed状态。 leader与 follower之间的日志也可能存在不一致的情况,follower或者少了一些日志,或者多了一些日志,如下图所示: 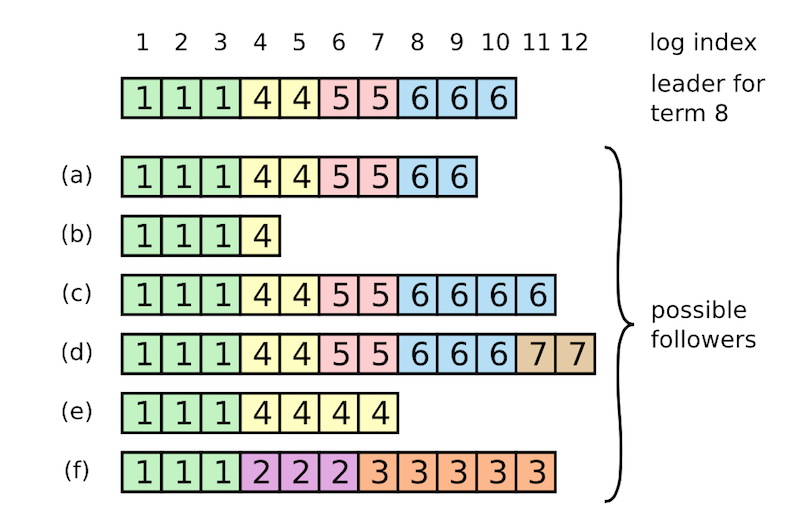 上图中最上面一行是leader的日志,而follower的日志存在以下情况:
上图中最上面一行是leader的日志,而follower的日志存在以下情况:
- a、b表示follower相比leader少了几条日志;
- c、d表示follower相比leader多了几条日志;
- e、f表示同时少了一些日志,又多了一些日志。比如f情况就是这台follower在任期2时被选为leader,刚添加3条日志还没有提交呢就宕机了,重启后被选为leader,又迅速收到5个写请求加了5条日志,还没提交又宕机了,此时再启动作为follower存在时的状态就是上图f的状态。
leader如果确定多数机器收到日志,自然可以提交。如果新leader刚被选出来,它会试图把多数机器上保存的日志(即使它自己没有这条日志)–也就是前任的日志也提交,但这未必保证一定成功,如下图所示: 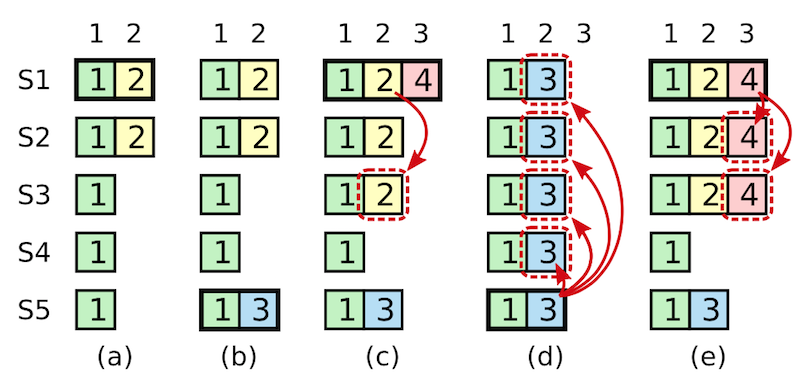 在上图中,d和e就是提交前任日志努力下可能导致的两种状况:
在上图中,d和e就是提交前任日志努力下可能导致的两种状况:
- 在a中,S1是leader,前写入日志2并只同步日志到S1和S2,还未到其他节点时就宕机了;
- 在b中,S5通过它自己、S3、S4的投票被选为leader,因此它并不知道日志2的存在。此时它收到client的新请求写入日志3,而刚写入日志3就宕机了;
- 在c中,S1重新被选为leader,此时它发现日志2还未被复制到多数follower,开始复制日志2。此时S1收到新请求,并记录了日志4;
- 在d中是第一种场景,此时老的日志2被复制到了S3上,然而此时的日志2虽然被S1、S2、S3多数节点持有,但却是通过2次任期完成的,且新任期里的日志4并未被复制到多数机器上,所以日志2并不能认定可以处于commited状态。若此时S1宕机,S5重新当选,则日志2会被覆盖丢弃,当然也包括未被复制到多数机器的日志4;
- 在e中是接着c的第二种场景,若日志4也被复制到S1、S2、S3这多数机器上,则日志2与日志3同时处于commited状态,永远不会被覆盖。
6、集群规模的配置变化
通常我们把raft集群配置为3或者5个节点,特别是5个节点时可以容忍2个节点宕机。这给我们平滑升级时带来了好处:1台台升级时仍然可以容忍1台宕机。但若我们的集群原来是3个节点的组合,却改为5个节点,如果这个过程是不停止服务动态完成的,这可能出现问题,如下图所示: 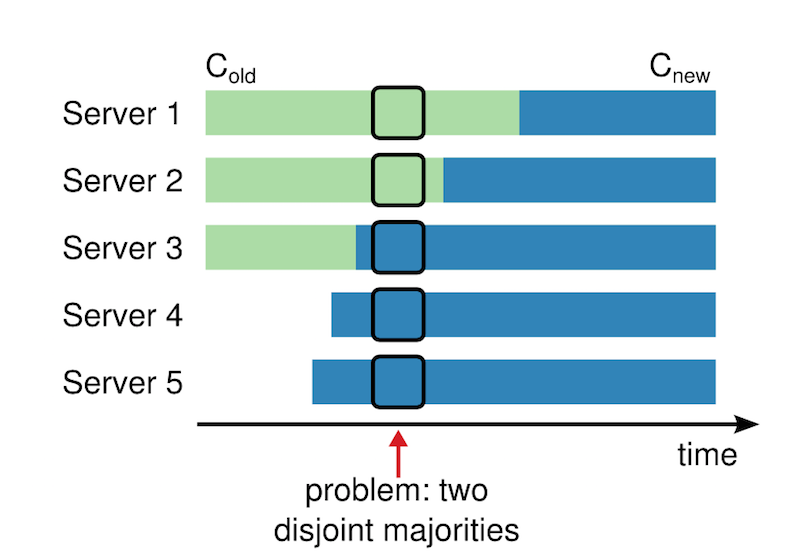 在上图中,绿色的老配置只有1、2、3这三台server组成集群,而在蓝色的新配置里则在1、2、3、4、5这五台server组成的新集群。于是,存在红色箭头指标的点,在该点上,可能1、2这两台server根据老配置在它们2个中选出第1个leader,而3、4、5根据新配置在它们3个中选出了第2个leader。同一时刻出现了2个leader,这样数据就会不一致。 为了解决上述问题,Raft提出了一个共同一致状态,该状态处于老配置和新配置生效的中间阶段。首先,我们设C(old)为老配置,而新配置为C(new),欲从C(old)状态置C(new),必须经历C(old,new)状态。其中,更新到C(old,new)以及C(new)时,仍然以复制日志的方式进行,即:先进行日志复制,当确定多数节点收到该日志后,则该日志为commited已提交状态。如下图所示:
在上图中,绿色的老配置只有1、2、3这三台server组成集群,而在蓝色的新配置里则在1、2、3、4、5这五台server组成的新集群。于是,存在红色箭头指标的点,在该点上,可能1、2这两台server根据老配置在它们2个中选出第1个leader,而3、4、5根据新配置在它们3个中选出了第2个leader。同一时刻出现了2个leader,这样数据就会不一致。 为了解决上述问题,Raft提出了一个共同一致状态,该状态处于老配置和新配置生效的中间阶段。首先,我们设C(old)为老配置,而新配置为C(new),欲从C(old)状态置C(new),必须经历C(old,new)状态。其中,更新到C(old,new)以及C(new)时,仍然以复制日志的方式进行,即:先进行日志复制,当确定多数节点收到该日志后,则该日志为commited已提交状态。如下图所示: 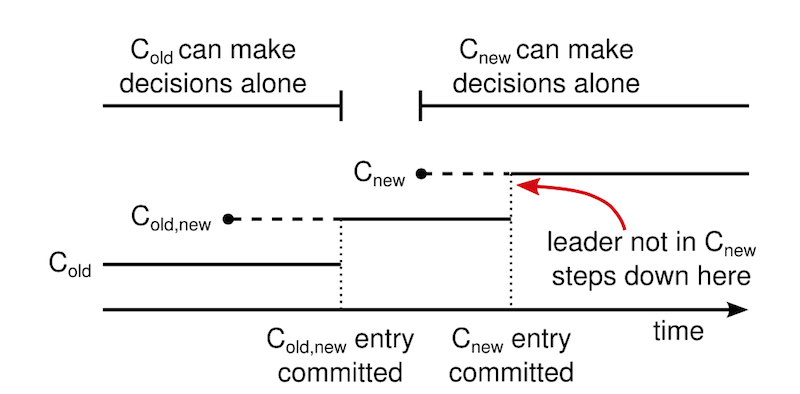 从上图中可以看到:
从上图中可以看到:
- 在C(old,new)日志开始复制时,仍然仅使用C(old)这一种配置,所以不会出现双leader;
- 而C(old,new)一旦进入commited提交状态,此时若leader宕机重新选举,则要求必须是具备C(old,new)的candidate才能被选为新leader;
- 之后,leader开始复制日志C(new),从这一刻起leader的新配置开始生效。
7、日志的优化
可以看到,Raft算法的核心就是leader选举以及日志复制。而日志的无限增长,必然带来性能问题,这是从工程角度必须解决的问题。日志表示的是过程,状态数据库表示的是结果;同样,我们可以定期把某一时间点之前的日志做成状态数据库,或者称为快照,仅保留该时间点后的日志,这样就可以大幅减少日志的数量。如下图所示: 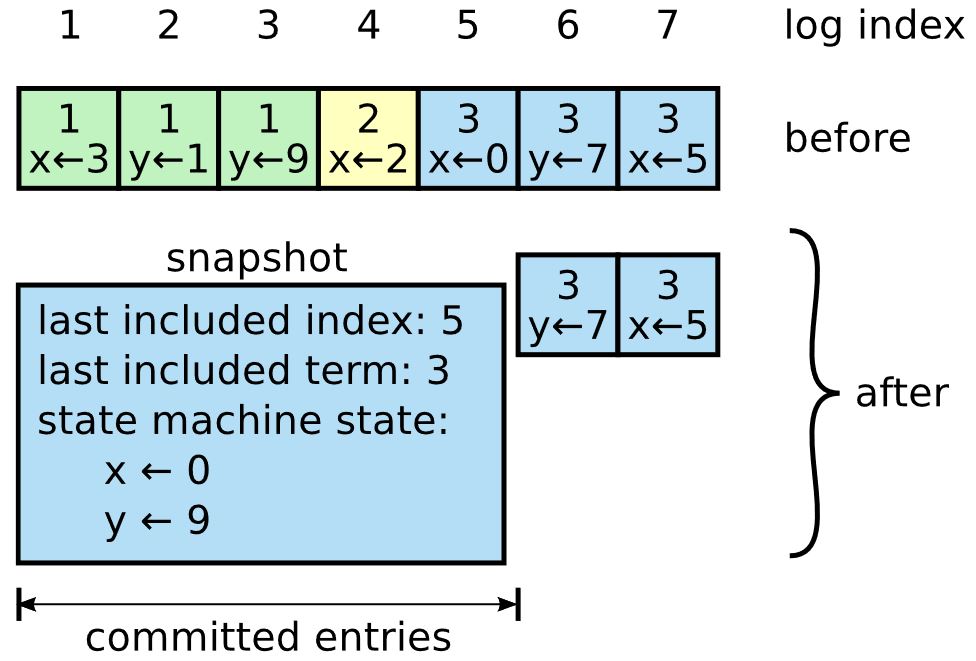 在上图中,原先的已经被提交的5条日志最终导致的状态是x=0&&y=9,故可以被快照替代,这便减少了日志量。
在上图中,原先的已经被提交的5条日志最终导致的状态是x=0&&y=9,故可以被快照替代,这便减少了日志量。
8、小结
Raft还有一个非常形象的算法演示动画,包含了一致性算法的由来、leader的选举、隔离网络下的leader选举、日志的复制等场景,请打开RaftUnderstandable Distributed Consensus链接观看。 学习Raft算法有助于我们理解分布式环境下的一致性解决方案,而且它确实比paxos好理解许多,可以作为我们的入门算法。